Scaling Apache Spark Applications on Azure: A Comprehensive Guide
If you’ve developed an Apache Spark application on your laptop and are now facing the challenge of processing terabytes of data, it’s time to scale up. The leap from local development to managing vast datasets requires a sophisticated approach. This is where Azure comes in, providing the infrastructure and services necessary for seamless scaling. In this guide, we’ll walk you through the steps to quickly scale your Spark application on Azure, ensuring you’re equipped to handle your growing data needs with confidence.
Creating an Azure HDinsight Cluster
If you’re reading this tutorial, you likely already have an Azure account. If you do not have one, you should first create one. Then create a new resource and search for “HDinsight”.

Azure HDInsight is a managed, open-source analytics service in the cloud for enterprises, offered by Microsoft. It allows the use of open-source frameworks such as Apache Hadoop, Spark, Hive, Kafka, HBase, and more for big data processing.

When you click on “Create” on the “Azure HDInsight” page, you will start creating the cluster. On this page, you will notice you need to register your subscription to use the HDInsight resource. When you click “Click here to register”, it will take you to this page.

Here, search for “HDInsight”, click on it, and then click register. After a few minutes, go back to creating an HDInsight cluster. Here, you need to select “Spark” as your cluster type & select the spark version you want.

Once you finish filling out all of the other required information, your next step is to set up storage for your cluster. Here, we are creating an Azure blob storage to store our cluster in.

We can skip over “Security & Networking” and go to “Configuration + Pricing”. On this page, you can select the nodes you want in your Apache Spark cluster. You will likely also get the error that your quota is not enough.
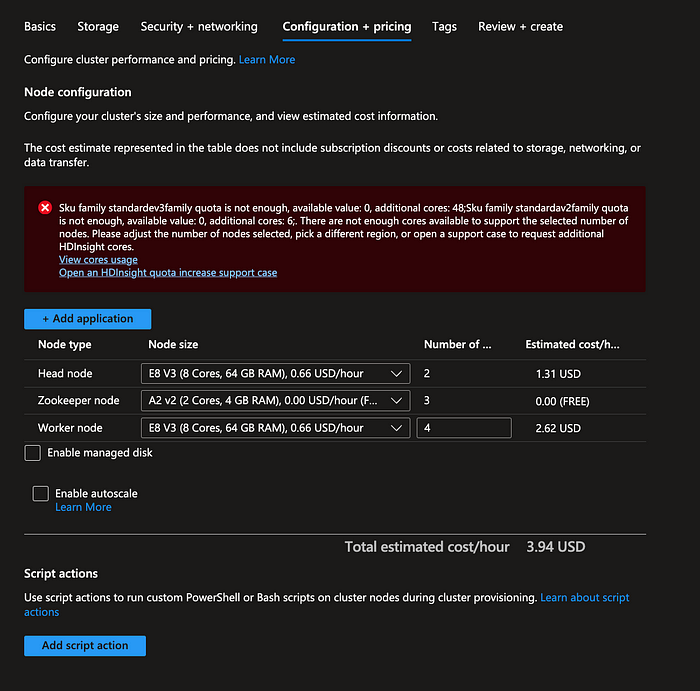
To fix this error, you will need to go to the home page of the Azure portal, open the side menu, then click on “Help + Support”.

Once you click on “Help + Support” you will need to click “Create a support request”. For the issue type you should select “Service and subscription limits (quotas)”, then select your subscription, then select “HDInsight” for your quota type.

Here, you should click “Enter details”. Once the side menu appears, select the location where you want your cluster & the SKU Family you want to request vCPUs. When I did this I requested for many different types and requested 100 cores from each. Azure responded to my requests within a few hours and gave me the requested quota increase. If this does not happen to you, check your emails and see if Microsoft is sending you emails about the quota increase.

Once Azure increases your quota limit, you can now configure the nodes you want to use in your Apache Spark cluster. You can additionally select the “Enable autoscale” option and configure how your cluster scales. Azure will also tell you how much your cluster will cost per hour.

Finally, hit next go to “Review and Create” and complete creating your Azure HDInsights cluster. This will start setting up your cluster. This process can take 5–10 minutes. Once initialized, you can click on the newly created resource and visit its page. Here, you can click on the URL and it will take you to your cluster’s dashboard. (Mine is blocked for security).
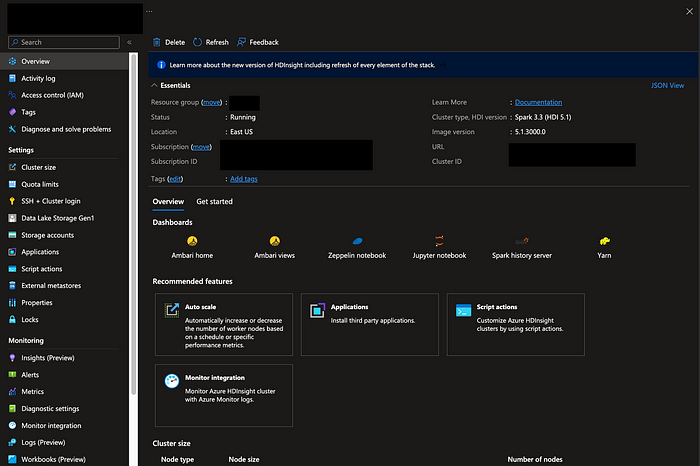
Clicking on the link will ask you for your ssh login credentials you configured when created the Spark cluster. Once you enter those, it will take you to this page, where you can manage your cluster's resources, configure the cluster, etc.

If you were already running spark applications locally, you are likely familiar with the Spark UI. To view the Spark UI of your cluster, you can click “Spark3” on the side menu, then on the right click “Spark3 History Server UI”. From here you can click on individual “App IDs” to view the job further.

This page will likely be empty as we haven't run any spark applications yet.
Congrats!

You now have successfully created a scalable infrastructure to run your Apache Spark applications. Now that this infrastructure is set up, you will want to run Spark jobs and further customize your nodes.
Here are additional tutorials you may find useful (adding once done):
[How to run spark applications with Livy on Azure apache spark HDInsight cluster]
[How to customize jar dependencies with Azure Apache Spark HDInsight cluster ]
[How to customize Python version with AzureApache Spark HDInsight Cluster]
I hope this article was helpful. If it helped you please leave a like! :)
